








昌平实验室陈明辰团队最新发布的 PPIFlow 框架,通过结合流匹配(Flow Matching)生成模型与物理能量引导的“计算机模拟亲和力成熟(In Silico Maturation)”策略,在零样本(Zero-shot)条件下成功实现了皮摩尔(pM)级亲和力结合剂&纳米抗体的生成。
本文将深入解析PPIFlow的算法逻辑,并将其与Chai-2、JAM-2、Latent-X2等前沿非开源模型进行多维度的严谨对比,探讨开源工具在推动药物发现精度与透明度方面的独特价值。
一、 计算设计的“最后一公里”
随着深度学习在蛋白质结构预测与生成领域的突破,从头设计蛋白质结合剂已成为可能。然而,现有主流方法(如RFdiffusion等)生成的分子虽然能结合靶点,但其亲和力往往停留在微摩尔(µM)级别。
为了达到治疗所需的纳摩尔(nM)或皮摩尔(pM)级亲和力,通常仍需依赖昂贵且耗时的体外实验(如酵母展示或噬菌体展示)进行亲和力成熟。这一计算设计与实际应用之间的差距,被称为“亲和力鸿沟(Affinity Gap)”。
近期,昌平实验室团队提出了 PPIFlow,这是一种集成式计算框架,旨在通过纯计算手段跨越这一鸿沟,无需湿实验优化即可直接生成高亲和力抗体与蛋白结合剂。
二、 PPIFlow:流匹配与物理能量的协同进化
PPIFlow 并非单一的生成模型,而是一套包含生成、优化与筛选的系统性流程。
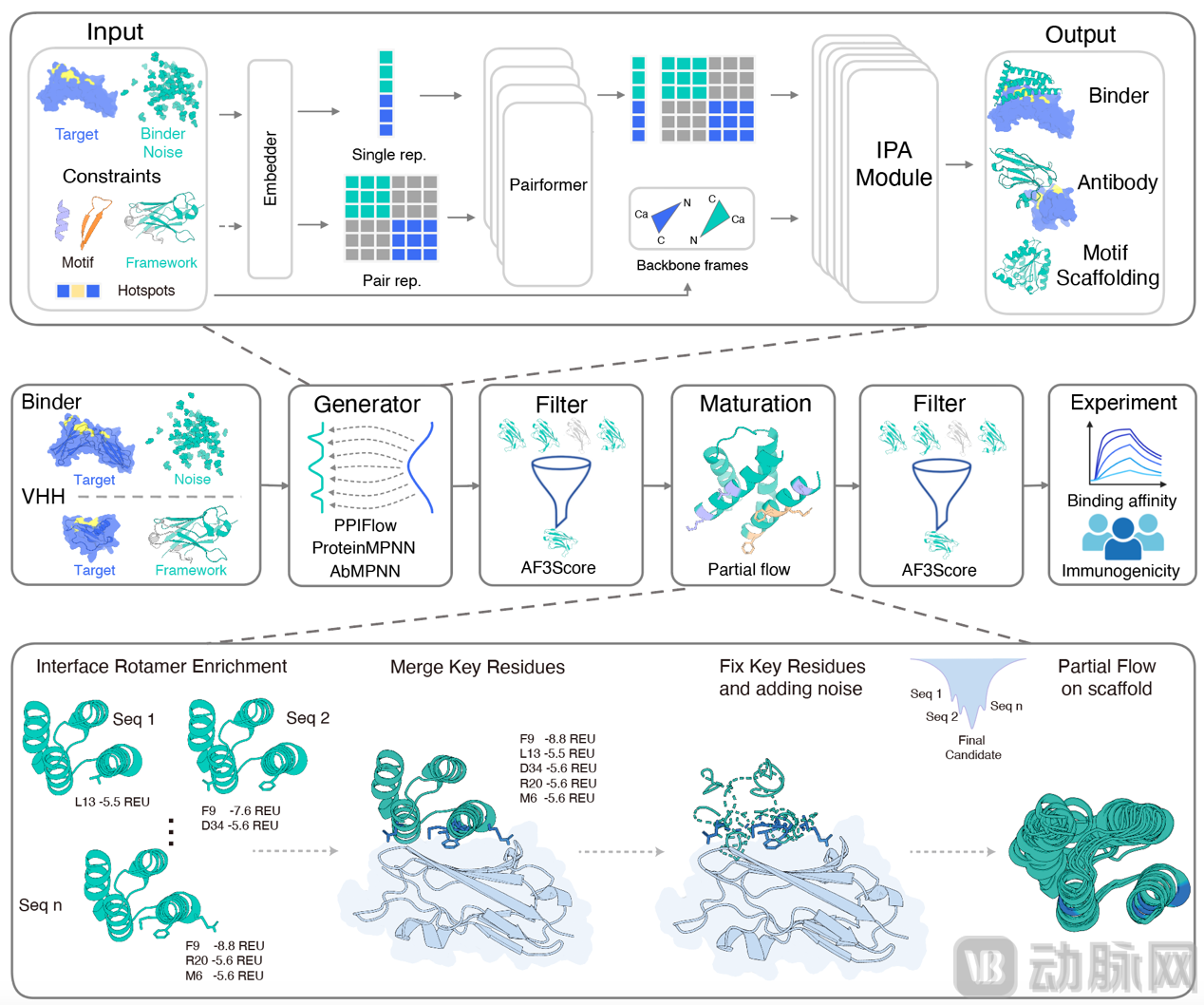
其实现高亲和力的核心在于两项关键技术创新:
1、基于流匹配的主干生成
不同于扩散模型,PPIFlow 采用了 SE(3) 流匹配(Flow Matching) 技术。该模型利用 Pairformer 架构显式推理残基对之间的几何与化学相互作用,将蛋白质主干的刚体变换建模为连续流。
相比于扩散模型,流匹配在训练稳定性和采样效率上展现出优势,能够更精确地以界面条件为约束进行结构生成。
2、计算机模拟亲和力成熟 (In Silico Maturation)
这是 PPIFlow 区别于其他模型的关键步骤,旨在模拟生物体内的亲和力成熟过程。该策略包含两个阶段:
● 界面关键氨基酸残基富集 (Interface Rotamer Enrichment): 利用 Rosetta 物理能量函数,精准识别结合界面上能量最优(< -5 REU)的“锚点”残基。
● 中间流加噪再生成 (Partial Flow Refinement): 固定上述关键锚点,对其余主干区域引入噪声并退回中间流状态进行重生成。
这种策略允许主干在保持关键相互作用的同时,微调界面堆积,从而逃离局部最优解,解决空间位阻,实现原子级别的紧密契合。
此外,为解决筛选效率问题,研究团队使用了 AF3Score——AlphaFold3 的“仅评分(Score-only)”版本,在保持高保真结构评估的同时,将计算效率提升了约 100 倍,使得大规模计算筛选成为可能。
3、实验验证:零样本下的皮摩尔级突破 在针对15个治疗性靶点的湿实验验证中,PPIFlow 展现了卓越的性能:
每个靶点送检30个进行湿实验验证,PPIFlow模型在迷你蛋白的生成上,7个靶点有6个可以达到pM级别的亲和力。
同时在纳米抗体的设计上,8个靶点中有7个成功获得结合配体,其中多个达到pM至nM亲和力,4个靶点产生的VHH Kd值进入single-digit nM以内。这些成功率对齐甚至优于国外的三家闭源模型。
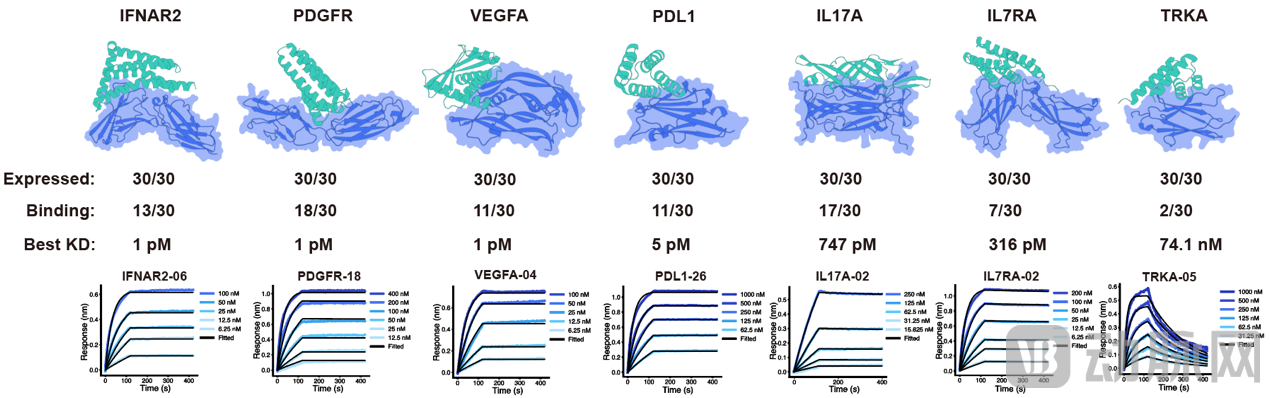
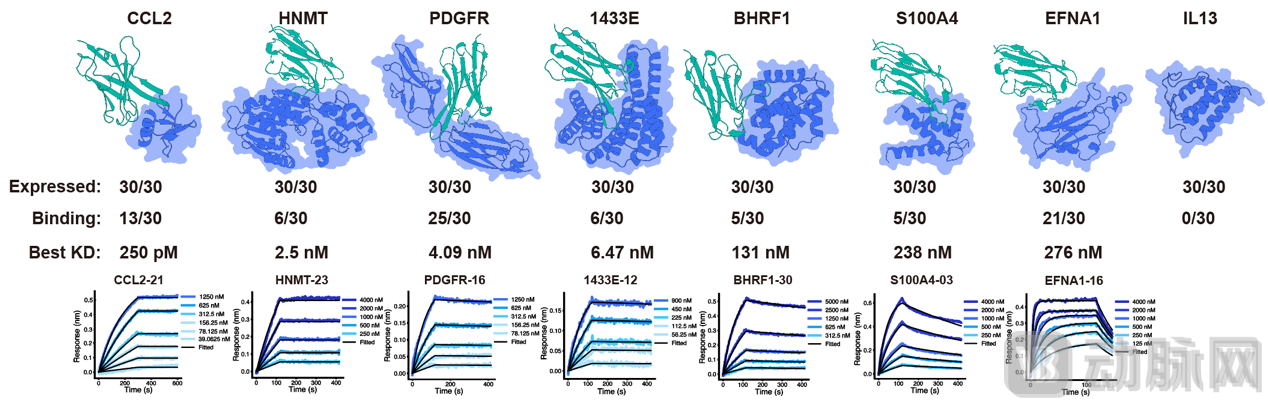
● 极致亲和力:在未经过体外优化的情况下,针对 IFNAR2, PDGFR, VEGFA, PD-L1的迷你蛋白结合剂亲和力达到了 10pM 以内;针对 CCL2 设计的纳米抗体(VHH)亲和力达到 250 pM。
● 高成功率:微型结合剂(Mini-binders)的总体命中率(< 1 µM)为 36.2%;VHH 抗体的总体命中率为 33.8%。
三、 横向评测:开源模型 PPIFlow 与非开源商业模型的对比
为了客观评估 PPIFlow 的技术地位,团队将其与近期发布的三个顶尖非开源商业模型——Chai-2 (Chai Discovery)、JAM-2 (Nabla Bio) 和 Latent-X2 (Latent Labs)——在五个核心维度上进行科学对比。
1、亲和力 (Affinity)
● PPIFlow:通过引入物理化学特征进行精修,PPIFlow 在亲和力上限上表现极佳。 其生成的 IFNAR2, PDGFR, VEGFA, PD-L1的迷你蛋白结合剂(<10 pM) 和 CCL2 VHH (250 pM) 证明了纯计算手段可以达到甚至超过部分商业模型的“零样本”亲和力水平。
● Latent-X2:同样展现了极高的亲和力,其针对 HDAC8 设计的 scFv 达到 26.2 pM,针对 PHD2 的大环肽达到 1.54 nM。
● JAM-2:在一半的测试靶点上实现了 pM 级或个位数 nM 级的亲和力(如 PRL < 100 pM)。
● Chai-2:微型蛋白可达 pM 级,但在抗体设计上通常处于 nM 级别(如 2.2 nM - 17 nM)。
● 结论: PPIFlow 在亲和力指标上与顶尖商业模型处于同一梯队,特别是结合物理能量优化的策略,使其在精细结构调整上具有独特优势。
2、成功率与效率 (Success Rate & Efficiency)
● JAM-2:表现出极高的鲁棒性。针对 16 个新靶点实现了 100% 靶点成功率,VHH-Fc 格式的平均序列命中率高达 39%。
● PPIFlow:VHH 设计靶点命中率为7/8,所有240 VHH的结合命中率为 33.8%,与 JAM-2 相当。其优势在于结合 AF3Score 实现了极低成本的计算筛选。
● Latent-X2:样本效率极高,每个靶点仅需测试 4-24 个 设计即可获得命中,靶点成功率为 50%。
● Chai-2:针对 52 个靶点的规模化验证中,抗体设计的平均命中率约 16%。
● 结论:PPIFlow 的序列命中率优于 Chai-2,与 JAM-2 接近,证明了其生成策略的高效性。
3、靶点广度与难度 (Target Scope)
● JAM-2:在膜蛋白(GPCRs)设计上具有显著突破,成功靶向 CXCR4/CXCR7 的正构位点。
● Latent-X2:独特优势在于大环肽设计能力,成功攻克胞内靶点(如 K-Ras)。
●Chai-2:验证了最广泛的靶点集(52个),并展示了多物种交叉反应设计能力。
● PPIFlow:目前主要验证于可溶性治疗靶点。虽然在特定高难度靶点(如 GPCRs)上的验证数据少于 JAM-2,但其通用架构为社区针对特定靶点的二次开发提供了基础。
4、开源与可及性 (Open Source & Accessibility) 这是 PPIFlow 最大的差异化优势。
● Chai-2/JAM-2/Latent-X2:均为商业闭源或限制性访问模型。
● PPIFlow:完全开源。代码和相关序列实验数据已在 GitHub 上公开。
这意味着全球科研人员不仅可以使用该工具,还能深入研究其“模拟成熟”的底层机制,并在此基础上进行改进。对于学术界而言,这是实现技术民主化的关键一步。
四、 总结与展望
昌平实验室的 PPIFlow 标志着抗体发现从“随机筛选”向“理性设计”迈出了坚实的一步。
与 Chai-2、JAM-2 和 Latent-X2 等优秀的商业模型相比,PPIFlow 在 亲和力精度 和 设计成功率 上已具备与其并驾齐驱的实力。
更重要的是,PPIFlow的开源属性 打破了高亲和力抗体设计的技术壁垒。它证明了不依赖庞大的私有数据和算力壁垒,通过精巧的算法设计(流匹配 + 能量引导的模拟成熟),同样可以解决生物制药领域的关键痛点。
这为整个蛋白质设计社区提供了一套透明、可复现且高性能的基础设施,有望加速创新药物分子的发现进程。
开源代码:
https://github.com/Mingchenchen/PPIFlow
" target="_self">https://github.com/Mingchenchen/PPIFlow开源论文:
https://www.biorxiv.org/content/10.64898/2026.01.19.700484v1
* 参考文献:
1.High-Affinity Protein Binder Design via Flow Matching and In Silico Maturation (Changping Laboratory)
2.Chai-2: Zero-shot antibody design in a 24-well plate (Chai Discovery)
3.JAM-2: Fully computational design of drug-like antibodies with high success rates (Nabla Bio)
4.Drug-like antibodies with low immunogenicity in human panels designed with Latent-X2 (Latent Labs)
5.nest.bio member | 陈明辰团队全球首发开源高亲和力蛋白&抗体Binder设计平台PPIFlow

















