









AlphaGo VS Lee Sedol
这段时间大家(主要是中韩英三国)都非常关注围棋人机对战。现在来看,结局真的不太重要的,其实当第一局Alphago赢了之后,Google的目的也就达到了(简直一石二鸟,不仅测试了自己的程序,还将人工智能从行业讨论推到了公众讨论层面),所以现在来说,无论结局如何,意义都已经不在胜负本身了。Google也不是无聊到花这么多钱就想弄个东西来虐虐大师们,还大张旗鼓地这么宣传,主要啊还是想弄清楚自己的程序是不是足够优秀了,之前算法的改进路径是不是对的,这个也就一前奏罢了,更多的野心体现在以后的专业领域(例如Google自己说在医疗领域)可以帮助人类更好的完成任务,至于怎么帮助,还得先从AlphaGo本身说起。
AlphaGo 是什么?
今年的Nature有一篇文章对AlphaGo进行了详细介绍(http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html),大意是说AlphaGo是一套为了围棋优化的设计周密的深度学习引擎,使用了神经网路加上蒙特卡罗树搜索,并且用上了巨大的谷歌云计算资源,结合CPU+GPU,加上从高手棋谱和自我学习的功能。这套系统比以前的围棋系统提高了接近1000分的Elo(围棋等级分),从业余5段提升到可以击败职业2段的水平,超越了前人对围棋领域的预测,更达到了人工智能领域的重大里程碑。
但是不久前才打败了欧洲冠军樊麾的Alphago,怎么会进步这么快,在这几天和李世乭的对弈中连拿两局呢?想弄清楚这一点我们得先了解下AlphaGo的系统构成,简单点说,Alphago就是一个黑盒子,但是他整合了不同机器学习技术、棋谱学习和自我学习、相对非常可扩张的architecture(让其充分利用谷歌的计算资源)、CPU+GPU并行发挥优势的整合。这套“工程”不但有世界顶级的机器学习技术,也有非常高效的代码,还有谷歌强大的计算资源。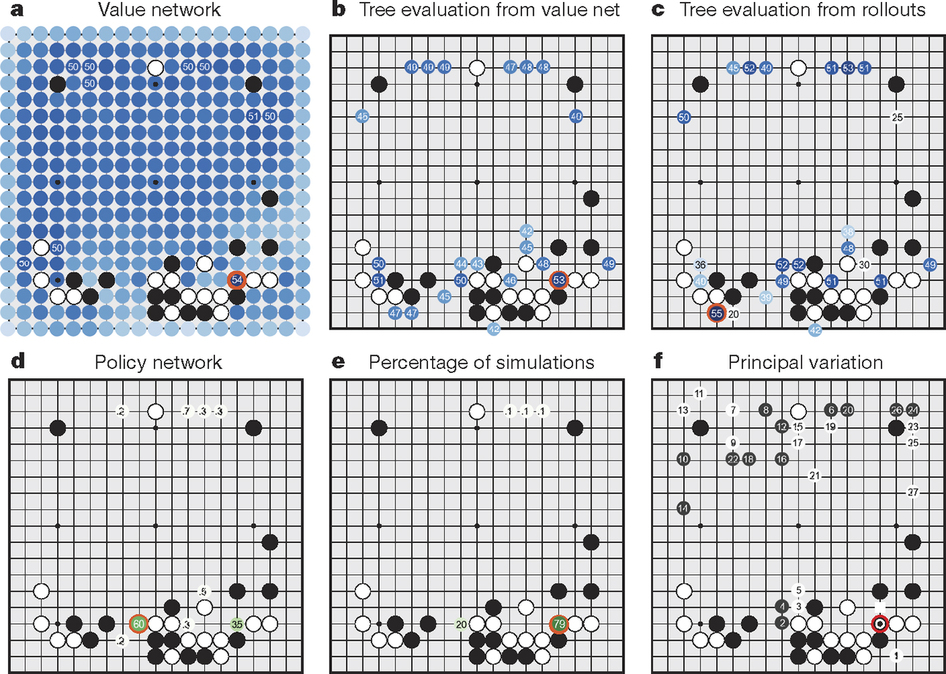
具体来说,这个系统主要由几个部分组成:
1. 走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。
2. 快速走子(Fast rollout),目标和1一样,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。
3. 估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。
4. 蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
当然继续解释下去就应该是电脑下棋的基本原理以及帮助电脑下围棋的两个核心模块“落子选择器”和“棋局评估器”的解释了,这样讲下去貌似有点跑题了,打住打住~(对AlphaGo工作原理感兴趣的同学可以看下这篇文章:http://www.dcine.com/2016/01/28/alphago)
背后的博弈
“国际象棋电脑程序想要在人类大师级(Master)选手中赢得一场比赛的唯一可能,是等到这位大师喝得烂醉、同时在下着50盘棋、并且犯下一个他一年才可能犯一次的错误时。”
“电脑永远也不可能击败特级大师(Grand Master)。”
“电脑永远也不可能击败实力强劲的特级大师。”
“也许电脑可以击败实力强劲的特级大师,但它永远也无法击败国际象棋世界冠军卡斯帕罗夫。”
“AlphaGo这次的比赛打败李世乭比较悬。”
“AlphaGo永远也不可能击败实力强劲的中国围棋选手,因为它根本就连不上服务器!”
想想人工智能一路走来也是挺不容易的,从最初的Deep Blue到现在的AlphaGo,AI科学家们总在想着法子来证明自己,但是就目前来看,AI究竟发展到什麽程度了呢?从这个点入手来分析这次棋局得背后博弈我觉得再合适不过了。
首先是在增强学习方面。在AlphaGo中,增强学习(Reinforcement Learning)所扮演的角色并没有想像中那么大。理想情况下,我们希望人工智能系统能在对局中动态地适应环境和对手的招式并且找到办法反制之,但是在AlphaGo中增强学习更多地是用于提供更多质量更好的样本,给有监督学习(Supervised Learning)以训练出更好的模型。所以这上面AlphaGo落了下风。
而情感方面,人类所蕴含的诸多情感,到今天为止也没有任何信息学家、生物学家能更证实感性作用在战略上是不占优势的。但是高度理性的特点确实在局部战略上可以获得优势。如果从另外一个侧面思考,我们所有人都能大体体会别人的感觉和情绪,那么这就铸就了另外一种信息传递和表达的通道,在社会网络和群体中的信息优势可以通过这种信息感知过程和表达过程发挥出长期的战略优势,如艺术的修养、文学的修养、同情等。这些优势相对直接的理性优势可以表达为幼年期儿童的哭闹,因为儿童明白感性也是可以通过向特定感性对象传达才能得意理解的,儿童明白向父母哭,但是从来不向IPAD哭,因为可能他们实验过几次,但是没有得到任何感性的回应。
而感性的回应从策略上讲是非常模糊的,所以很难界定回应的真实战略意义,一般我们就称其为情感回应。从博弈上来看是信息和策略的运用,而感性系统和理性系统交叉在人类的行为中,所以从AI的角度,更加难理解李世石的每一步决策,因为这些决策虽然是相同的神经网络做出的决策,但是却受到激素、经验、情感的多重干预,对AI来讲可能包含着某种更加深意的策略行为,而ANN是纯的算法和数学,所以它并没有能力理解Lee所传递的综合信息,所以在双方博弈的时候,只有很少的部分能回应他。KBA转播中李世石情不自禁的转头看向Alpha GO,但是这一弊Alpha GO是不能够理解的。人类的博弈游戏从来都不是纯理性的结果,是理性和感性交织组合的结果。两个人类棋手的相互直视间其实完成了理性、感性、社会优势、生理优势多方面的交叉比较,而Alpha GO只能是个下棋工具,情感方面人类是占有优势的。
从计算量来衡量,我觉得双方的计算和信息输入量是均等的。Alpha GO的能耗比可能更高一些,李世石的能耗是225千卡/小时,而Alpha GO的能耗约是280000瓦特时, 从能耗比方面李是更加绿色环保的围棋大师。从神经计算信息量来测量,Lee的神经系统装机总量小于AlphaGo,有2亿个神经元。AL GO大约有 200亿个计算单元(一次0/1换量为2),最麻烦的是李世石之能调动1-3%的神经元量(他下棋的时候),而Alpha Go可以调动90-100%的装机总量。所以他们在计算力上有生物功能上的差距。这种差距是生物需氧量的限制,因为活动大量神经元系统需要很多能量,调动全部脑神经需要更多氧气,人类的呼吸能力不能达标。其次是过度氧化衰老的问题,过度氧化产生后果就是衰老和糖化。所以我们在能量效应上来看,这是一场不太公平的对决。
总得来看,AI和实际人类的自然构造结构虽然在一定程度上逼近了,但是人类系统过于复杂,想高度模仿或者超越人类系统,哪怕是最容易模仿的神经系统,从物理环境、介质、能耗、复杂系统各个方面均很难超越。似乎这和事实很不相符啊,毕竟AlphaGo昨天才又赢了一盘。但是前面说过了,Lee是在和机器下棋,确切地说是和算法对弈,所以上面的这些优势也就在一定情况下变成了劣势。
估计这些我们普通人也看不大懂,也没什么兴趣看,毕竟离我们的生活有点远。其实有个问题我一直不理解,为啥AI科学家执意要让机器人往情感方向上走呢?这里就和大家讨论下这个问题。
做自己的事
看看Apple的Siri,Microsoft的Cortana、小冰对于自然语言的理解,不得不承认在近些年上有巨大的进步,但是距离人类的语言水平依然差距甚远。
这里我们所说的AI,并不是真正的和人类一样,具有独立思维,能够进行独立判断。目前所有号称所谓的AI应该是没有这方面能力的,只是由一堆天才将事先设计好的数学模型用计算机能理解的方式,告知计算机,然后根据这个模型进行模式判断,从事某个专一功能。当然这个过程中,可能会对模型本身进行修正,也就是所谓的"自主学习"
那么一个人机对战我们可以理解为一个棋类大师对战一堆数学怪才,是的,没错,就是一堆。由这一堆怪才分析了大量的棋谱等各种资料,建立一套庞大且复杂的体系,最终建模。然后依托于计算机强大的计算能力。在这里,AI首先得益于背后强大的科研团队,获得了大量研究成果,其次将这些研究成果交由电脑,根据实际情况判断并处理,再次依赖电脑强大的计算能力。在这一过程中,AI拥有得天独厚的优势,先是规避了计算机没有独立分析能力的劣势,有专业人员将分析结果直接告诉电脑,其次,极大发挥了电脑善于数学运算的优势。相对于人脑,也许每秒只能做几次加法运算,而电脑可以做几亿次,几十亿次每秒的运算,这大概就是所说的“勤能补拙”吧。
而人脑的优势则在于抽象、分析、理解能力,比如一个老朋友10年没见面,10年后的某一天也许见面,这个人的长相、衣着都有了比较大的变化,但人脑依旧可以迅速给出反应,这是我以前的同学/同事/上司...相比于电脑,简直不能说甩了几条街,是甩了无数个宇宙。
所以人和机器在优势上就有着本质的区别,那么为什么不让机器做自己擅长的事,人类的事儿则由人类完成呢?如果这样,是不是就不会有机器取代人类之类的说法了呢?这里只是提出了几个疑问,问题的解答仍然需要AI界的科学家来完成。
回到正题,昨天人机大战第二盘结果出来之后,看到很多朋友表示兴奋之余又不紧背后发凉,惊呼AI将统治人类,或者是不久的将来AI智力将超越人类,我觉得这个不能这么看,角度不对。
人工智能与人类智能
电脑战胜国际象棋冠军,其实也摧毁了国际象棋这项运动,国际象棋的受关注程度大幅降低。这次的角色换成了人工智能和围棋。这次比赛结束后,尽管人与人之间的对弈还会继续,但是棋手心理阴影的面积和人类自己对这项运动的评价,只有自己知道。
昨天朋友圈就有一棋友发文:“难道以后的棋神就是一台机器了?OMG~”
其实换个角度来想想,这事儿还挺好玩的。大家应该知道,与之前的围棋系统相比,AlphaGo较少依赖围棋的领域知识,但还远未达到通用系统的程度。职业棋手可以在看过了寥寥几局之后明白对手的风格并采取相应策略,一位资深游戏玩家也可以在玩一个新游戏几次后很快上手,但到目前为止,人工智能系统要达到人类水平,还是需要大量样本的训练的。可以说,没有千年来众多棋手在围棋上的积累,就没有围棋AI的今天。
这也就是说,如果我们自身没法继续提高自己,按照模式学习这套办法来看,就算再多几个月,它能够收集使用的人类顶尖棋手的新棋谱不会增加很多,利用这个机制能够获得的提升会很有限。这就好比两个业余1段的小孩,如果让他们自己不断对弈也许能提升到2段,但如果没有更多的高手信息(例如棋谱或者指导),那他们俩哪怕每天互相下一千万盘棋,仍然提升不到4、5段。
因为目前机器学习技术的一大瓶颈,是需要大量的高质量样本才能构建出强大的模型;但是人类在许多任务上往往只需很少的样本就能显著提升能力,这是目前的机器学习技术做不到的。
另一方面,AlphaGo还不是一个可以自主运行的系统,还需要人的参与;也就是说,人类的智慧进步过程中,通过输入和输出的持续反馈,人脑的硬件结构并没有直接被外界干预,而人脑的思维(算法)又是完全依赖于各种细胞和分子构件的硬件,相比之下,AlphaGo可能还不会通过输入和输出的各种反馈而自己改变算法(不知道实际情况是不是这样),而是要依靠人类设计者团队去优化算法。人类的知识进步本来就是拉马克式遗传或者叫获得性遗传,因此,至少目前来看AlphaGo仍然应该被视为人类知识积累在计算机硬件辅助下的一种延伸,而不是一种简单的并行或竞争关系。
所以我们应该乐观点(这是促使我们进步的好机会呀),机器是人类创造的,机器学习的提升速度取决于我们人类自己,我们应更多得从这次比赛中看到机器的缺陷和人类的优势所在。在今天Lee得到了他关于AlphaGo的第一个样本(几个月前的AlphaGo和今天的AlphaGo,从机器学习角度看已经不是同一个东西),他将如何根据这个样本来提高自己对付AlphaGo的能力?能提高到什么程度?这个真的非常值得观察,因为这一定程度上代表了该任务上人类顶级专家的学习能力。

Alpha go ,where to go
其实这部分才是笔者最为关注的,即:如何用好AlphaGo?
其实早前Hassabis也很明白地表露过自己的想法:“现在我并没有做太多AI编程方面的事情,更多得则是对于公司未来的直觉思考,空闲时我会想一些当天在文章和新闻中看到的东西,思考我们的研究如何和那些东西结合起来。因为商业化才是每个公司的未来方向。目前大部分大部分人工智能系统应用范围都很“窄”,训练预设程序的机器去执行特定任务,除此之外再没什么了,但我们致力于构建一个“通用学习机器”,即一套能像生物系统一样学习的灵活、自适应的算法,仅使用原始数据就能从头开始掌握任何任务。我希望最终我们能将这些技术用于重要的真实世界的问题,例如气候模型或者复杂的疾病分析,很酷不是吗?”
说到疾病分析,Watson应该算AI在这上面应用的典范了,其第一个真正严肃的应用就是作为癌症医学辅助诊断手段。从2011年开始,Watson就一直在协助肿瘤科医生,它能够对病人的病历进行深入的分析,并且还能将该病历和存储的其它来源的相关病历、临床专业知识和学术研究进行比对和筛选;这使得Watson甚至能够自行推导出连医生自己也未曾考虑过的治疗方案,这些工作长期以来都是人类无法完全掌握的工作,而在机器面前,却非常简单。但根据Google一贯的野心,应该远不止这样。抛开一些幻想的因素,我们来从各大科技公司的动作来整理一下思路(投资界的网友已整理好,这里借用一下,感谢!):
Google
2013年:收购深度神经网络公司DNNresearch。
2014年:收购深度学习公司DeepMind。
2015年:无人车上路测试,预计2020年商业化;开源深度学习系统TensorFlow代码。
2016年:Google DeepMind AlphaGo系统打败围棋高手;Google与半导体新创企业Movidius合作深度学习手机;欲将神经网路RankBrain结合搜索引擎。
微软
2014年:推出个人语音助理Cortana。
2015年:推出亚洲聊天机器小冰;收购R语言商业方案提供商Revolution Analytics与以色列文本分析新创公司Equivio;推出应用测年龄http://how-old.net和测双胞胎http://TwinsOrNot.net。
2016年:收购智能输入公司SwiftKey;开源深度学习语音图像识别CNTK;推出测你是哪种狗应用http://What-dog.net。
IBM
2012年:收购人力资源管理公司Kenexa。2014年华生已应用在医疗、金融、法律、学术、煮饭。
2015年:收购自然语言处理服务商AlchemyAPI、IBM宣布开源机器学习平台SystemML。
2016年:软银机器人Pepper已成功导入IBM超级电脑华生。
Facebook
2015年:正式成立人工智能研究团队;展示人工智能助理M;公布人工智能硬件框架Big Sur并开源;收购语音识别技术Wit.ai。
2016年底:打造AI管家;训练人工智能系统下围棋。
苹果
2013年:收购自动语音识别技术公司Novauris。
2015年:收购口语识别新创VocalIQ和影像辨识新创公司Perceptio。
2016年:收购人脸及情绪识别技术的新创公司Emotient;雇用教Siri运动知识的软件工程师。
Tesla
2014年:投资模仿人脑的人工智能公司Vicarious。
2015年:投资非盈利人工智能中心OpenAI,防止AI危害人类;推出电动车自动驾驶系统。
Amazon
2012年:收购机器人仓库设备商Kiva Systems。
2013年:收购文字转语音公司Ivona和语音识别App Evi Technology。
2015年:用人工智能技术发现假评论及评分;推出语音助理Echo;发布Alexa开发套件。
从这里来看,AI目前仍然在做一些非常底层的事,也就是逻辑方面的计算,作为一种工具,我想这是AI最好的归宿了,想象力与创造力是我们人类的专利,因为机器没有自我思想,它们的思想就是我们的设计。
虽然大公司在AI医疗上似乎没有太大的动作,但不可否认这仍然是一片蓝海。目前在医疗上,利用人工智来为病人望闻问切似乎还不大靠谱,但是,利用人工智能解决医疗面临的核心问题:安全与质量、管理与效益,是现在就可以实现的。比如:在医学诊断系统是否可以借助AI实现流程标准化,将医生的角色上升为系统的监控与纠错?从目前来看,Enlitic, 3SCAN, ENTOPSIS这三家初创公司在这方面做得还不错;而在药品评估领域,已经有ADMET Predictor这样的,利用计算机模拟药物药理,代谢和副作用的评估软件了。那么,能否利用人工智能/机器学习+超级计算机+临床实验&医疗大数据,借助“模糊测试思想”,帮助分离出病毒/细菌/肿瘤细胞的靶向特征作用点,从而帮助发现并加速各种新型药品的开发?或者是优化已经存在的药物效果?亦或降低个体化医疗的成本?抱歉,这个已经不是我这个非专业人士所能解答的了,欢迎诸位前辈指教。
行文至此,也应该可以告一段落了,其实以上的内容就是笔者对这几个问题的一些看法:
1.为什么Alpha go的胜利会让我们觉得如此惊天动地?
2.这次人机对战意味着什麽?能为我们带来什麽?棋局的背后有何深意?
3.机器与人类的思维方式到底有哪些不同呢?Alpha Go真的在模仿人脑下围棋吗?
4.DeepMind 掌门人 Demis Hassabis对人工智能文化、生活与工作的观点有何独特之处?
5.对待人机对战,我们应该持什麽样的立场?
身在这个年代,真的很幸运,能够见证希格斯玻色子的发现,能够见证引力波的探测,现在又见证了人工智能的标志性事件。身在这个年代,真的很不幸,谁都无法预测,这些潘朵拉的盒子一旦打开,里面会出现什么。
过去几天的比赛对于AlphaGo来说,不过是其海量的围棋样本库中多增加了微不足道的一个样本而已,而对于Lee,则是一种不同的经历。即使AlphaGo最终将获胜,但我仍然相信人类的潜力,今天的比赛,Keep Fighting,Lee!


















