









AI 工作流程很复杂。构建一个 AI 应用程序不是一项简单的任务,因为它需要各种具有领域专业知识的各种利益相关者来大规模开发和部署应用程序。数据科学家和开发人员需要方便地访问软件构建块,例如模型和容器,它们不仅安全、高性能,而且具有构建其 AI 模型所需的基础架构。
在构建完应用程序之后,DevOps 和 IT 管理人员需要一些工具,这些工具可以帮助他们在各种设备之间无缝地部署和管理这些应用程序,包括本地设备、云设备或边缘设备。
NVIDIA 构建了 NGC 目录,通过提供易于访问的 GPU 优化软件,例如容器、预先训练的模型、应用框架和构建 AI 应用程序所需的 Helm 图表,来简化和加速 AI 工作流程。
在这篇文章中,我们将展示如何使用 NGC 目录和它的核心底层特性,例如集合、NGC 私有注册表和 AI 构建块来构建和部署一个口罩检测应用程序,作为一个示例,该示例展示了 development-to-deployment 管道。
随着 NGC 的推出,NVIDIA 简化了整个用户体验,并将所需的相关容器、模型、代码和 Helm 图表集中在一个地方,而无需在目录中定位和协调各种独立的构建块。
您可以找到针对特定任务的工作负载的 NGC 集合,如自动语音识别或图像分类,以及行业 SDK,例如 NVIDIA Clara 或迁移学习工具包 (TLT)。如果您希望构建一个用于对象检测的应用程序,那么在目录中搜索该集合,您将在一个地方找到所有相关资产。
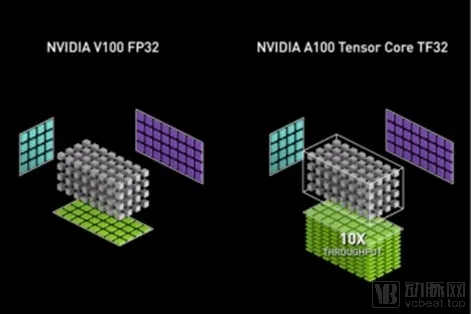
NVIDIA Ampere GPU 架构引入了第三代 Tensor Cores,以及新的TensorFloat32 (TF32) 模式加速 FP32 卷积和矩阵乘法。TF32 模式是AmpereGPU 架构上 32 位变量的 AI 训练的默认选项。它为单精度DL工作负载带来了 Tensor Core 加速,而不需要对模型脚本进行任何更改。
使用本机16 位格式 (FP16/BF16) 的混合精度训练仍然是最快的选择,只需要模型脚本中的几行代码。表1显示了与 FP32 CUDA 核相比,A100Tensor Cores 的数学吞吐量。值得指出的是,对于单精度训练,A100 提供的数学吞吐量比上一代训练GPU V100 高 10 倍。
TF32 是 GPU 架构 Ampere 一代 Tensor Core 中新增的一种新的计算模式。点积计算,它构成了矩阵乘法和卷积的构建块,将 FP32 的输入轮化到 TF32,在不损失精度的情况下计算产品,然后将这些产品积累到 FP32 输出中。
TF32 只是作为 Tensor Core 操作模式公开,而不是一个类型。内存中的所有存储和其他操作完全保留在 FP32 中,只有卷积和矩阵乘法在乘法之前将它们的输入转换为 TF32。相反,16位类型提供存储、各种数学运算符等等。

















