









近日,北京医鸣技术有限公司自主研发的大规模医学语言模型1M-MedBert在中文医疗信息处理挑战榜CBLUE2.0中参加了中文医疗命名实体识别-CMeEE任务,成绩名列第一!领先来自于多家国内知名的人工智能企业及科研院校队伍。这充分体现了医鸣自研的1M-MedBert模型,在中文医疗信息处理领域,具有领先地位!北京医鸣技术有限公司将基于1M-MedBert模型,进行更多的医学领域自然语言处理任务,并在未来开源1M-MedBert模型,促进中文医疗信息处理领域发展。
中文医疗信息处理评测基准CBLUE(Chinese Biomedical Language Understanding Evaluation)是中国中文信息学会医疗健康与生物信息处理专业委员会在合法开放共享的理念下发起,由阿里云天池平台承办,旨在推动中文医学NLP技术和社区的发展。参加挑战榜的单位有云知声,思必驰,西安交通大学,中科院自动化所等国内知名的机构。
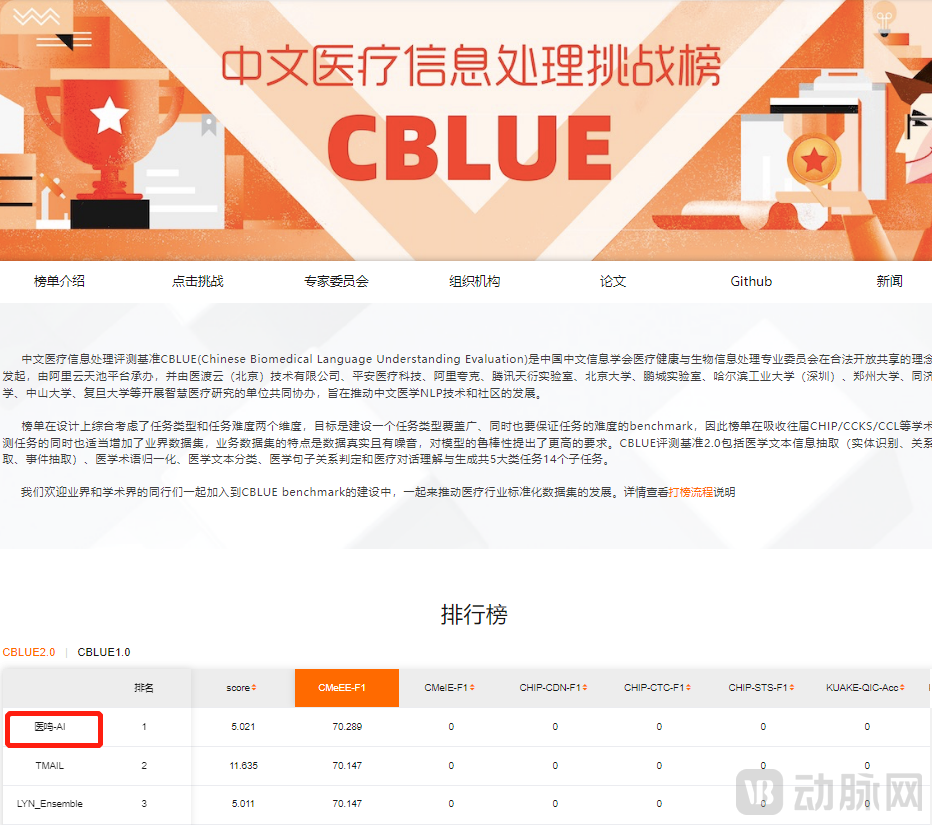
图1 医鸣科技在CBLUE2.0-CMeEE任务排名
医疗数据处理的最大难点在于病历文书等非结构化数据的准确处理,北京医鸣通过自身的数据积累优势、医学专业优势,结合人工智能技术,开发了医鸣自有的大规模医学语言模型1M-MedBert,可以支持医学命名实体识别,医学文本分类等多种医学领域自然语言处理下游任务。
比如,在与医院合作的医学文本不良事件识别任务中,北京医鸣使用1M-MedBert作为医学语言模型,结合命名实体识别算法,进行了医学文本的命名实体提取,并使用医学规则库对命名实体进行不良事件判断。该方法已获得国家医学中心的认可, 1M-MedBert医学语言模型具有极大的实际应用价值。

















