









2016年,成都盛世君联生物技术有限公司(后简称“盛世君联”)创立。8年时间,盛世君联搭建起三千亿级多样性的真实生物药物库,并在此基础上创建干湿试验结合的大分子AI药物研发平台BioAI。
8年时间,如何从真实生物药物库进军AI药物研发平台?又如何攻破AI药物研发的高壁垒?动脉网对盛世君联CEO刘江海进行了专访。
动脉网:盛世君联是做生物药物发现、优化服务起家的,为什么会自发创建以AI为驱动的药物研发?
刘江海:AI概念从爆火到稍微降温的这三年,产生了很多优秀的AI大模型。当他们应用于数据庞大、交互频繁的生活领域时,对传统工作产生了碾压式胜利。但在公开数据相对较少、数据验证反馈较慢的专业领域,比如生物医药领域,AI又该如何进入呢?我个人是非常相信AI终究会改变药物的研发模式,但是作为生物医学背景的研发人员,我看不懂AI模型中的数学公式、计算机代码,更不会编程和修改参数,因此无法直接使用AI开展工作。同时,像大多数已经习惯于传统方法的研究者一样,我也会时刻怀疑AI生成数据的准确性。
本质上,这是算法模型开发者与生物药物研发者之间存在着认知、语言、理解、和路径逻辑上的差异,在真实场景中变成了“你不懂我、我不懂你”的无效交流和应用障碍。我们并不缺乏优秀的AI大模型,而是缺少将这些大模型在专业领域进行深度应用的方式方法。过去的几年,我们一边积极接触和使用最新AI工具成果,一边与国内多家头部的AI医药企业合作或服务,在这个过程中积累了很多真实经验。我们认为,高质量的标签化数据、基于生物学逻辑的AI算法和“傻瓜式”的应用软件,是AI打开生物药物研发大门的钥匙。
>>>>
动脉网:您可以具体谈谈AI用于生物药研发的深入思考吗?比如什么才是高质量的标签化数据?盛世君联用于AI学习训练的数据从哪儿来?
刘江海:高质量的数据是AI学习训练的基础,在生物医药领域尤其需要真实的、验证的、带生物学标签的数据。在过去的7年时间,盛世君联搭建了“三千亿级多样性”的真实生物药物库,包括人源抗体库、纳米抗体库、多肽库、affibody库、CAR-T库和TCR库等。依赖此平台,盛世君联自有项目已获得了千万级带多重生物学标签的自有数据,且仍在持续高速增长中。
数据质量和独创性由持续精进的技术壁垒保护。盛世君联药物库能达到“三千亿级多样性”源于公司核心技术之一——“全合成库技术”,基础方法在2016年引进自美国的基因泰克公司,此后5年实现了2次重要的本地技术突破,一是“多位点突变效率从最初的20%提高到100%”,二是“单次构建1011多样性合成库”。目前可以做到在2周内构建1011多样性全合成库,3个月构建1013多样性全合成库,这使得盛世君联建库效率和序列多样性都远远超过传统技术路线(如小鼠杂交瘤、B 细胞分选)的同行。
利用全球领先的全合成库技术和“三千亿级多样性”的真实生物药物库,盛世君联从2019年开始为众多的头部药企提供了生物药物库构建和生物药物发现优化等技术服务,在业内建立了良好的口碑,也对药物研发过程中的真实痛点和难点有了丰富的行业一线认知。
在保证数据质量、真实性和独创性的基础上,对AI的学习和训练来说,数据的连续性、标签化、高低排序也很重要。通常AI训练使用的是公共数据库的数据,这些数据在序列的相似性上是碎片化的,在序列的标签化上是单一的、无关联的,但我们生物药物库获得的序列具有极佳的连续性和关联性。
首先,全合成库技术的定点连续突变使得生物药物库的序列呈现连续的氨基酸变化,且与生物学属性是一一对应的,这样AI就容易学习到单个或者多个氨基酸突变所对应的生物学意义。
第二,通过定向设计和筛选,全合成库可以使不同的序列带上相同的生物学标签,也可以使相同或者相似的序列带上不同的生物学标签。
第三,全合成库生产的序列是直接排序的,筛选获得的序列会按照亲和力大小、稳定性高低、激活能力强弱进行呈现。
第四,通过正筛和负筛,全合成库生产的数据也是阳性数据和阴性数据明显分群的。
因此我们的真实生物药物库可以获得具有非常丰富标签组合的、氨基酸变化连续的、生物属性排序的药物序列,更适应“多任务协同优化”的AI应用理念。基于这些优点,盛世君联的全合成库从2021年起已先后为国内的7家AI企业提供数据包或者定向生产数据。
另外,全合成库技术也是对AI预测数据进行高通量验证的强力工具。AI能否优于传统人力工作流,验证和迭代效率也是关键。在小分子药物领域,AI已经可以针对某一疾病靶点,设计出20个以内的小分子候选物,因此比较容易进行逐个验证。但在大分子药物领域,AI针对一个靶点,预测出来的大分子候选物往往在1010以上,无法实现逐一的表达和验证。全合成库针对AI预测的序列进行建库和高通筛选,可以在短时间内完成>1012个大分子候选物的快速验证。目前盛世君联对AI预测数据进行验证的最大多样性超过1020,是为国内一家头部AI企业的提供的商业服务项目。
>>>>
动脉网:为什么要用生物学逻辑去搭建AI算法?盛世君联是怎么做的呢?
刘江海:我们知道小分子药物是较小的刚性结构,与靶点蛋白的结合面积小,空间相对稳定,使用基于能量或者氨基酸理化性质为基础的AI模型,通过几何学的近似模拟,并不会丢失太多关键的真实信息。但是大分子药物与靶点的结合面积大,两者的结合始终处在相互吸引、相互拉扯的动态过程之中。
我们团队成员因为有结构生物学和生物医学背景,所以始终认为蛋白大分子本身或者之间的动态变化,通过能量和物理学计算的数据去训练AI是不合理的,这会导致AI预测的大分子药物在结构上不准确、在生物活性的判断上不准确,带来药物开发的不确定。
那AI技术应如何赋能大分子药物研发呢?能不能开发一个基于生物学,尤其是蛋白质结构和进化为底层逻辑的AI模型?我们独有的全合成库技术具有持续、定向的生产海量、高质量数据的能力。如果我们能用这些带生物学标签的、连续的、排序的蛋白序列训练AI,同时特别关注这些序列的生物进化和结构生物学逻辑,那就能够获得一个独特的生物学AI模型(BioAI)。
因此,2021年我们开始搭建自己的AI技术团队。建立之初,团队就设立了明确目标:
(1)不单独开发Transformer和超参数大模型,使用授权的大模型和独有数据开发适用于生物药物研发的预训练模型、专业模型,就是我们的BioAI。
(2)同时以BioAI为基础开发专业软件,帮助每位科研工作者解决生物药物研发的具体工作。
BioAI以蛋白质的氨基酸序列为代码,关联多重生物学标签,训练中关注蛋白进化中的序列随机性和偏好性、抗体序列的保守性和多样性、蛋白质结构的多态性、以及蛋白-蛋白作用界面刚性和柔性序列。BioAI可能并不清楚为什么40多亿年进化会演变为今天蛋白质的特定序列,但是它通过比对和关联,一定会将序列代码与生物属性一一对应,进而预测出特定位置的氨基酸改变所带来的生物属性改变,实现智能化的蛋白质定向进化。这正是生物药物生成和优化所需要的。
BioAI的搭建需要不同的专业背景的人才共同实现。为了解决海量数据的分类和高维关联问题,盛世君联引入了拥有微软、甲骨文多年工作经验的黄琛作为Co-CEO,同时负责生成式AI的应用。为了从生物学逻辑出发训练AI,盛世君联聘请清华大学生物学博士曾昕担任CTO和多年从事AI医学应用的张康教授担任CSO。同时,为了快速开发专业软件,盛世君联还引入了拥有微软多年工作经验的沈云担任首席架构师,负责开发“傻瓜式”的生物药物研发软件。
值得欣喜的是,张康教授主导的、盛世君联参与的,通过生物学逻辑AI研究蛋白-蛋白相互作用(PPI)的论文在今年8月发表在Nature Medicine上。
动脉网:您提到要用BioAI做“傻瓜式”软件,可以详细讲讲,如何帮助科研工作者能够用上AI来解决研发问题?
刘江海:有了AI模型不代表可以直接将其用于生物药物研发的具体项目中。盛世君联做的专业软件叫“BioAI for Scientists”。我们希望这个软件可以实现“AI四化”:
AI专业化: 聚焦AI大模型在生物药物专业领域的深度应用,使用独有的真实数据进行预训练,让AI在垂直应用上不断迭代、演进,使AI预测数据接近甚至优于传统实验获得的数据。
AI场景化:将生物药物研发中具体实验进行数字场景设定,每个场景分步骤匹配AI算法进行计算、预测,每个步骤嵌入生物药物研发的逻辑、规则,来控制AI输出的结果质量,实现AI替代传统研发流程。
AI工具化:将专业化和场景化的AI,通过软件工程,集成、整合成能够解决生物药物研发关键问题、步骤的软件、APP,通过“一键输入、一键输出”的傻瓜操作,让每一个科学家、研究者、技术员、学生都能轻松使用AI。
AI高通化:通过持续训练和真实验证,将AI训练为最优秀的科学家,实现近乎实时的结果反馈,同时能够并行实施多项工作流程,极大提升药物研发和科学研究的效率。
2023年10月,经过3年的技术沉淀和大量数据验证,盛世君联的“BioAI for Scientists”系列软件已经正式上线。现在科研工作者只用登录盛世君联“BioAI驱动的生物药物研发”门户网站,选择相应服务类型、提交相应序列数据,即可等待AI筛选结果。常规AI计算的时间不超过1周。
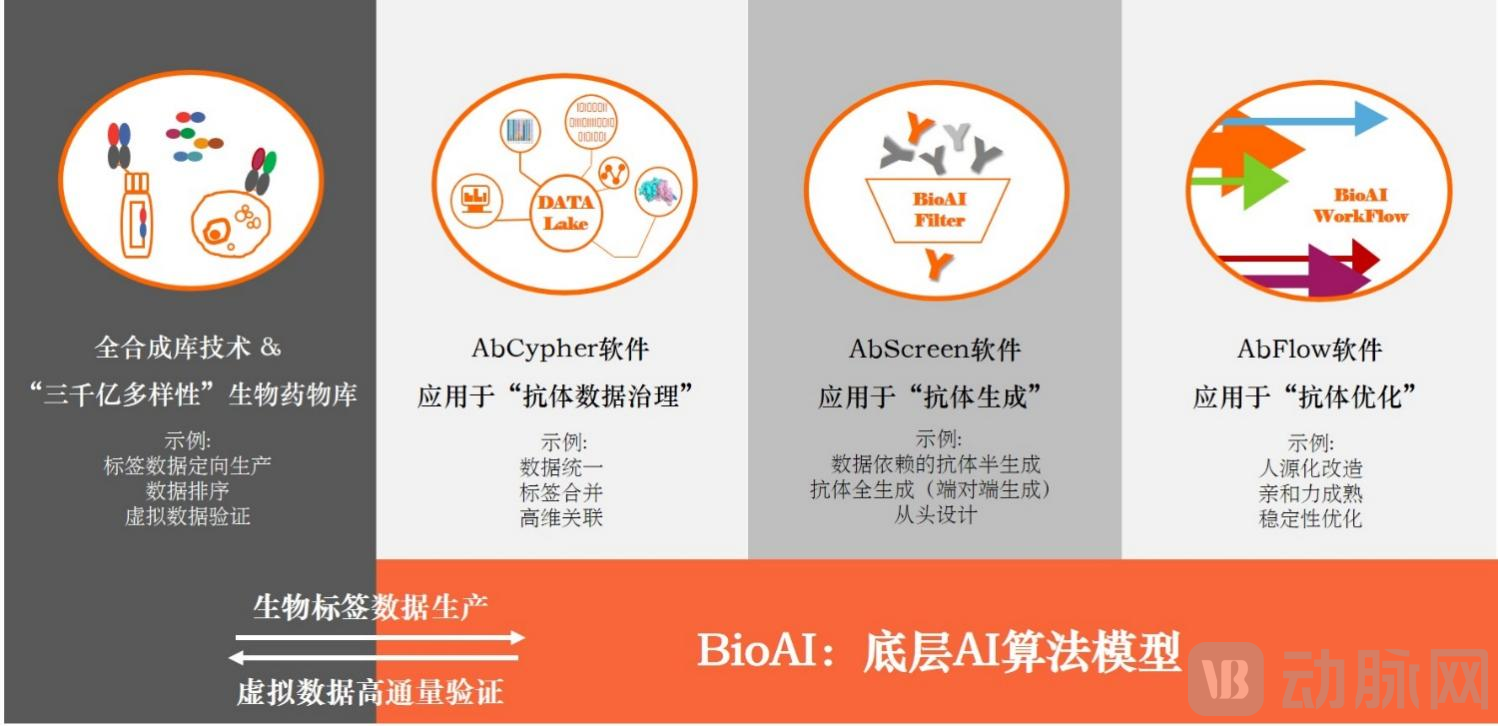
BioAI for Scientists结构图
“BioAI for Scientists”依托盛世君联自有技术平台和生物学人工智能(BioAI),搭建了包括真实数据生产、AbCypher数据处理、BioAI算法、AI软件、高通量真实验证的闭环式、干湿轮转、自动迭代的AI生物药物研发软件系统。通过“一键输入靶点序列、一键输出药物序列”、“一键输入母本序列、一键输出优化序列”的简单操作,为每一位药物研发人员提供高效、便捷、准确的AI技术服务软件。最重要的在于通过在软件的步骤间嵌入生物药物研发规则,保证输出结果不弱于传统实验结果,达到生物药物研发的专业性。
>>>>
动脉网:请问您对BioAI未来的期许是什么?或者说盛世君联未来的奋斗目标是什么?
刘江海:BioAI其实存在着很强的可拓展性,其应用不止能作用于生物药物的发现,还可以拓展到生物酶、理化性质研究、mRNA下游验证、下游工艺开发等。虚拟生物药物库是无限大、无限多样性的,这是真实药物库无法比拟的优点。这意味着药物源头的池子更大、更有序,将带来无限多样性的药物发现。
我认为盛世君联已来到生物药AI发展的第二阶段:从人类经验到AI智能、从有限发现到无限发现。尽管我们目前的AI还不能摆脱自然法则和数据依赖,但是我相信经过2-3年的技术发展,AI是可以进行到药物创造阶段的。当完成了足够多的数据训练和项目哺育后,AI将不再需要数据的预训练,从而升级成为药物创造者AI,也就是第三阶段的GenAI。它将成为无边界的药物创造者,创造出全新的、从未有过的药物。从自然发现到AI“无边界”创造,这将意味着生物医药真正达到了AI智能。这也是盛世君联未来奋斗的目标。

















